单表查询(select):
- 单表全部字段查询:select * from 表名 ;
- 单表部分字段查询:select 字段1,字段2,字段3,…from 表名;
- 单表查询条件查询:select 字段1,字段2,… from 表名 where 查询条件;
常见的查询条件查询表达式:
- and:(多个表达式同时满足) select * from 表名 where 表达式1 and 表达式2 and 表达式3;
- or:(多个表达式只需满足其中一个)select * from 表名 where 表达式1 or 表达式2 or 表达式3;
- >:(满足字段大于该值的所有条件)select * from 表名 where 字段1>数值1;
- <:(满足字段小于该值的所有条件)select * from 表名 where 字段1<数值1;
- >=:(满足字段大于等于该值的所有条件)select * from 表名 where 字段1>=数值1;
- <=:(满足字段小于等于该值的所有条件)select * from 表名 where 字段1<=数值1;
- !=或者<>:都表示不等于,select * from 表名 where 字段1!=数值1;
多表查询:
- 笛卡尔积:select * from 表名1,表名2 ;
- 多表查询全部字段:select * from member,invest where member.id = invest.memberid;
- 多表查询部分字段:select member.RegName,member.LeaveAmount,invest.Amount from member,invest where member.id =invest.memberid;
由于很多时候表名比较长而且难记,所以就用表名的别名来代替表名:select m.regname,m.leaveamount,i.amount from member as m, invest as i where m.id=i.memberid;(as 可以去掉,多表查询字段可能会重复,字段名前面加上表名.字段名)
排序(默认是升序):
- 升序 asc:select * from 表名 where order by 需要排序的字段名1,需要排序的字段名2 asc;
- 降序 desc:select * from 表名 where order by 需要排序的字段名1,需要排序的字段名2 desc;
高级查询:
- 数据集in/not in :in存在于某个数据集里面,not in不存在于某个数据集里面 。
- 模糊查询like:用%匹配, %关键字、关键字%、%关键字%,分别匹配关键字前面、后面、中间的值
- 常见的聚合函数:count()统计函数、max()最大值、min()最小值、sum()求和、avg()平均值。
select 字段名,聚合函数 from 表名 group by 字段名(一般为主键);
- 分组group by:分组查询
- 去重distinct:去除重复
- 两者之间 between:在两者之间
- 分页limit:(limit m,n) m为偏移量=要显示的第一位数-1 ,n=要显示的数据个数
数据集in/not in :
用法:select * from 表名 where 字段名1 in(数据1,数据2);
用法等同于select * from 表名 where 表达式1 or 表达式2;
数据集:可以是具体的某几个值:值a,值b,…..值n,也可以是通过一个子查询得到的数据集
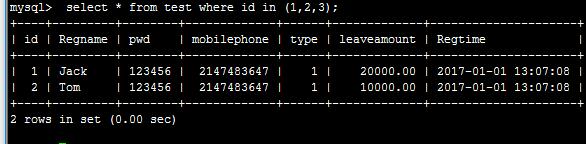
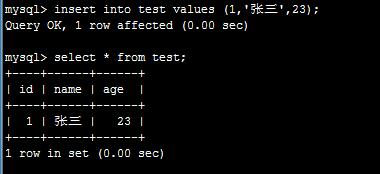
比如: select * from test where id in (1,2,3);
模糊查询like:
select * from 表名 where 字段名 like %关键字/关键字%/%关键字%/占位符_;
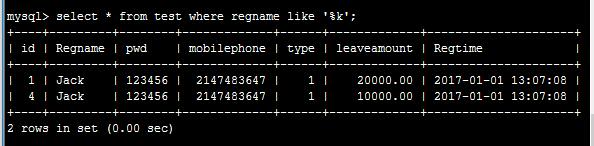
- 以关键字结尾匹配:比如:select * from test where regname like ‘%k’;
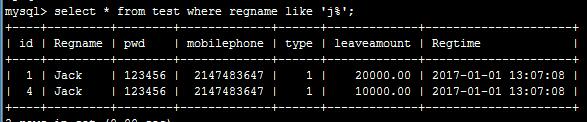
- 以关键字开头匹配:比如:select * from test where regname like ‘j%’;
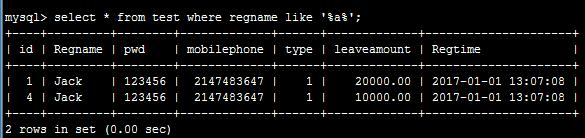
- 关键字在中间匹配:select * from test where regname like ‘%a%’;
- 占位符匹配 ”_“:比如手机号码固定中间4位是8888,select * from test where regname like ‘___8888____’;
分组group by:一般按照主键id分组
用法:select 字段名,聚合函数 from 表名 where group by 分组字段名;
- 聚合函数:对一组值执行计算并返回单一的值的函数,聚合函数经常与select 语句的group by 一同使用,常见的聚合函数有:sum()、count()、avg()、min()、max()
- having:分组后,想在分组结果的基础上继续过滤的话,就必须把过滤条件写在having后面
多字段进行分组:select t1.id ,t1.regname ,sum(amount) from member t1,invest t2 where t1.id=t2.memberid group by t1.id ,t1.regname ;
注意:多表查询一定要先写关联条件在分组
比如:
2、从loan表分组查询,按照memberid进行分组,计算用户个数,且投资金额大于100000
select *,count(*) from loan group by membered having amount>100000;
4、去重distinct:
去除查询结果中的重复数据
用法:select distinct 字段名 from 表名;
比如:查询所有投资的用户id (重复的memberid就去除了)
Select distinct memberid from invest;
5、两者之间 between:
使用场景:条件字段的取值处于两个数据范围内的情况
用法:select 字段名 from 表名 where 字段名 between … and …..;
比如:找出用户表可用余额在100000到400000的用户信息(包含边界值)
select * from member where leaveamount between 100000 and 400000;
或select * from member where leaveamount>=100000 and leaveamount<=400000;
分页limit:
使用场景:去查询结果的前n条
用法:select 字段名 from 表名 limit m,n;(m为偏移量=要显示的第一位数-1 ,n=要显示的数据个数)
常用函数:
- 数值相关函数
- 日期函数
- 字符串函数













评论前必须登录!
注册